
Kylin
Apache kylin是一个开源的分布式分析引擎。它通过ANSI-SQL接口,提供基于hadoop的超大数据集(TB-PB级)的多维分析(OLAP)功能。
整理 by 杜锡俊
OLAP简介
OLAP的历史与基本概念
OLAP全称为在线联机分析应用,是一种对于多维数据分析查询的解决方案。典型的OLAP应用场景包括销售、市场、管理等商务报表,预算决算,经济报表等等。
最早的OLAP查询工具是发布于1970年的Express,然而完整的OLAP概念是在1993年由关系数据库之父EdgarF.Codd 提出,伴随而来的是著名的“twelvelaws of online analytical processing”. 1998年微软发布MicrosoftAnalysis Services,并且在早一年通过OLE DB for OLAP API引入MDX查询语言,2001年微软和Hyperion发布的XML forAnalysis 成为了事实上的OLAP查询标准。如今,MDX已成为与SQL旗鼓相当的OLAP 查询语言,被各家OLAP厂商先后支持。
OLAPCube是一种典型的多维数据分析技术,Cube本身可以认为是不同维度数据组成的dataset,一个OLAP Cube 可以拥有多个维度(Dimension),以及多个事实(Factor Measure)。用户通过OLAP工具从多个角度来进行数据的多维分析。通常认为OLAP包括三种基本的分析操作:上卷(rollup)、下钻(drilldown)、切片切块(slicingand dicing),原始数据经过聚合以及整理后变成一个或多个维度的视图。
ROLAP和MOLAP
传统OLAP根据数据存储方式的不同分为ROLAP(Relational OLAP)以及MOLAP(Multi-dimensionOLAP)
ROLAP 以关系模型的方式存储用作多维分析用的数据,优点在于存储体积小,查询方式灵活,然而缺点也显而易见,每次查询都需要对数据进行聚合计算,为了改善短板,ROLAP使用了列存、并行查询、查询优化、位图索引等技术
MOLAP 将分析用的数据物理上存储为多维数组的形式,形成CUBE结构。维度的属性值映射成多维数组的下标或者下标范围,事实以多维数组的值存储在数组单元中,优势是查询快速,缺点是数据量不容易控制,可能会出现维度爆炸的问题。
大数据时代OLAP的挑战
近二十年内,ROLAP技术随着MPP并行数据库技术的发展,尤其是列存技术的支持下,实现了分析能力大幅度的跨越提升,同时伴随着内存成本的进一步降低,单节点内存扩展性增强,集群单节点的查询性能实现了飞跃,内存数据库的实用性跨上了一个新台阶,这些技术进步共同作用的结果是类似的技术基本覆盖了TB级别的数据分析需求。 Hadoop以及相关大数据技术的出现提供了一个几近无限扩展的数据平台,在相关技术的支持下,各个应用的数据已突破了传统OLAP所能支持的容量上界。每天千万、数亿条的数据,提供若干维度的分析模型,大数据OLAP最迫切所要解决的问题就是大量实时运算导致的响应时间迟滞。
Kylin 相关研究
Apache kylin介绍
OLAP全称为在线联机分析应用,是一种对于多维数据分析查询的解决方案。典型的OLAP应用场景包括销售、市场、管理等商务报表,预算决算,经济报表等等。
最早的OLAP查询工具是发布于1970年的Express,然而完整的OLAP概念是在1993年由关系数据库之父EdgarF.Codd 提出,伴随而来的是著名的“twelvelaws of online analytical processing”. 1998年微软发布MicrosoftAnalysis Services,并且在早一年通过OLE DB for OLAP API引入MDX查询语言,2001年微软和Hyperion发布的XML forAnalysis 成为了事实上的OLAP查询标准。如今,MDX已成为与SQL旗鼓相当的OLAP 查询语言,被各家OLAP厂商先后支持。
OLAPCube是一种典型的多维数据分析技术,Cube本身可以认为是不同维度数据组成的dataset,一个OLAP Cube 可以拥有多个维度(Dimension),以及多个事实(Factor Measure)。用户通过OLAP工具从多个角度来进行数据的多维分析。通常认为OLAP包括三种基本的分析操作:上卷(rollup)、下钻(drilldown)、切片切块(slicingand dicing),原始数据经过聚合以及整理后变成一个或多个维度的视图。
Apache kylin是什么。
Apache kylin是一个开源的分布式分析引擎。它通过ANSI-SQL接口,提供基于hadoop的超大数据集(TB-PB级)的多维分析(OLAP)功能。
只需三步,kylin即可实现超大数据集上的亚秒级(sub-second latency)查询。
- 确定hadoop上一个星型模式(wiki:Star schema)的数据集。
- 构建数据立方体(wiki:Data cube)。
- 可通过ODBC, JDBC,RESTful API等接口在亚秒级的延迟内查询相关数据。

为什么引入kylin。
由于数据是基于hadoop分布式存储,所以比mysql的伸缩性好。
提供hadoop上超大数据规模( 百亿行级别的数据)的亚秒级(sub-second latency)SQL查询,相对于hive的离线分析,可做到实时查询。
可无缝整合其他BI工具,如Tableau, PowerBI,Excel。
Apache kylin 生态系统

- Apache kylin核心:Kylin的(OLAP) 引擎由元数据引擎、查询引擎、任务引擎、存储引擎组成。另外,它还有一个rest服务器对外提供查询请求的服务。
- 可扩展性:提供插件机制支持额外的特性和功能。
- 与其他系统的整合:可整合任务调度器,ETL工具、监控及告警系统。
- 驱动包(Drivers):提供ODBC、JDBC驱动支持与其他工具(如Tableau)的整合。
Apache kylin内部解剖
Apache kylin的核心概念
表(Table) ):表定义在hive中,是数据立方体(Data wiki:Data cube)的数据源,在build cube 之前,必须同步在 kylin中。
模型(model):模型描述了一个星型模式的数据结构,它定义了一个事实表(Fact Table: Wiki:Fact_table)和多个查找表(Lookup Table:Wiki:Lookup_table)的连接和过滤关系。
立方体(Cube):它定义了使用的模型、模型中的表的维度(dimension:Wiki:dimension))、度量(measure:Wiki:measure) ,一般指聚合函数,如:sum、count、average等)、如何对段分区( segments partition)、合并段(segments auto-merge)等的规则。
立方体段(Cube Segment):它是立方体构建(build)后的数据载体,一个 segment 映射hbase中的一张表,立方体实例构建(build)后,会产生一个新的segment,一旦某个已经构建的立方体的原始数据发生变化,只需刷新(fresh)变化的时间段所关联的segment即可。
作业(Job):对立方体实例发出构建(build)请求后,会产生一个作业。该作业记录了立方体实例build时的每一步任务信息。作业的状态信息反映构建立方体实例的结果信息。如作业执行的状态信息为RUNNING 时,表明立方体实例正在被构建;若作业状态信息为FINISHED ,表明立方体实例构建成功;若作业状态信息为ERROR ,表明立方体实例构建失败!作业的所有状态如下:
1,NEW - This denotes one job has been just created. 2,PENDING - This denotes one job is paused by job scheduler and waiting for resources. 3,RUNNING - This denotes one job is running in progress. 4,FINISHED - This denotes one job is successfully finished. 5,ERROR - This denotes one job is aborted with errors. 6,DISCARDED - This denotes one job is cancelled by end users.
Apache kylin的工作机制
Apache kylin 能提供低延迟(sub-second latency)的秘诀就是预计算,即针对一个星型拓扑结构的数据立方体,预计算多个维度组合的度量,然后将结果保存在hbase中,对外暴露ODBC, JDBC,RESTful API的查询接口,即可实现实时查询。
数据立方体一般由Hive中的一个事实表,多个查找表组成。预计算的过程在kylin中就是 Cube) 的build过程,如下图:
当前Apache kylin构建(build)数据立方体,采用逐层算法(By Layer Cubing)。未来的发布中将采用快速立方体算法(Fast Cubing)。下面简单介绍一下逐层算法:
一个完整的数据立方体,由N-dimension立方体,N-1 dimension立方体,N-2维立方体,0 dimension立方体这样的层关系组成,除了N-dimension立方体,基于原数据计算,其他层的立方体可基于其父层的立方体计算。所以该算法的核心是N次顺序的MapReduce计算。
在MapReduce模型中,key由维度的组合的构成,value由度量的组合构成,当一个Map读到一个key-value对时,它会计算所有的子立方体(child cuboid),在每个子立方体中,Map从key中移除一个维度,将新key和value输出到reducer中。直到当所有层计算完毕,才完成数据立方体的计算。过程如下图:

在数据立方体计算完毕后,有一个任务(Convert Cuboid Data to HFile),其职责是将reduce输出的运算结果(Cuboid Data)转化成Hbase中的存储载体(HFile/io/hfile/HFile.html)),最终将HFile 加载到Hbase表中便于查询。其中表的rowkey由维度组合而成,维度组合对应的度量值构成了column family,为了查询减少存储空间,会对RowKey和column family的值进行编码,默认编码是Snappy。

整个数据立方体的构建流程如下:

- 根据Cube定义的事实表以及维度表,利用Hive创建一张宽表
- 抽取事实表上的维度的distinct值,将事实表上的维度以字典树方式压缩编码成目录,将维度表以字典树的方式编码
- 利用MapReduce从第一步得到的宽表文件作为输入,创建 N-Dimension cuboid,然后每次根据前一步的结果串行生成 N-1 cuboid, N-2 cuboid … 0-Cuboid
- 根据生成的Cuboid数据量计算HTable的Region分割策略,创建HTable,将HFile导入进来
Apache Kylin与传统的OLAP一样,无法应对数据Update的情况(更新数据会导致Cube的失效,需要重建整个Cube)。面对每天甚至每两个小时这样固定周期的增量数据,Kylin使用了一种增量Cubing技术来进行快速响应。
Apache Kylin的Cube可以根据时间段划分成多个Segment。在Cube第一次Build完成之后会有一个Segment,在每次增量Build后会产生一个新的Segment。增量Cubing依赖已有的CubeSegments和增量的原始数据。增量Cubing的步骤和新建 Cube的步骤类似,Segment之间以时间段进行区分。
增量Cubing所需要面对的原始数据量更小,因此增量Cubing的速度是非常快的。然而随着CubeSegments的数目增加,一定程度上会影响到查询的进行,所以在Segments数目到一定数量后可能需要进行CubeSegments的合并操作,实际上MergeCube是合成了一个新的大的CubeSegment来替代,Merge操作是一个异步的在线操作,不会对前端的查询业务产生影响。
合并操作步骤如下:
- 遍历指定的Cube Segment
- 合并维度字典目录和维度表快照
- 利用MapReduce合并他们的 N-Dimension cuboid
- 将cuboid转换成HFile,生成新的HTable,替代原有的多个HTable
Apache Kylin对传统MOLAP的改进
计算Cube的存储代价以及计算代价都是比较大的, 传统OLAP的维度爆炸的问题Kylin也一样会遇到。 Kylin提供给用户一些优化措施,在一定程度上能降低维度爆炸的问题:
Cube 优化:
* Hierachy Dimension
* Derived Dimension
* Aggregation Group
Hierachy Dimension, 一系列具有层次关系的Dimension组成一个Hierachy, 比如年、月、日组成了一个Hierachy, 在Cube中,如果不设置Hierarchy, 会有 年、月、日、年月、年日、月日 6个cuboid, 但是设置了Hierarchy之后Cuboid增加了一个约束,希望低Level的Dimension一定要伴随高Level的Dimension 一起出现。设置了Hierachy Dimension 能使得需要计算的维度组合减少一半。
Derived Dimension, 如果在某张维度表上有多个维度,那么可以将其设置为Derived Dimension, 在Kylin内部会将其统一用维度表的主键来替换,以此来达到降低维度组合的数目,当然在一定程度上Derived Dimension 会降低查询效率,在查询时,Kylin使用维度表主键进行聚合后,再通过主键和真正维度列的映射关系做一次转换,在Kylin内部再对结果集做一次聚合后返回给用户
Aggregation Group, 这是一个将维度进行分组,以求达到降低维度组合数目的手段。不同分组的维度之间组成的Cuboid数量会大大降低,维度组合从2的(k+m+n)次幂至多能降低到 2的k次幂加2的m次幂加2的n次幂。Group的优化措施与查询SQL紧密依赖,可以说是为了查询的定制优化。 如果查询的维度是夸Group的,那么Kylin需要以较大的代价从N-Cuboid中聚合得到所需要的查询结果,这需要Cube构建人员在建模时仔细地斟酌。
数据压缩:
Apache Kylin针对维度字典以及维度表快照采用了特殊的压缩算法,对于Hbase中的聚合计算数据利用了Hadoop的LZO或者是Snappy,从而保证存储在Hbase以及内存中的数据尽可能的小。其中维度字典以及维度表快照的压缩考虑到DataCube中会出现非常多的重复的维度成员值,最直接的处理方式就是利用数据字典的方式将维度值映射成ID, Kylin中采用了Trie树的方式对维度值进行编码
distinct count聚合查询优化:
Apache Kylin 采用了HypeLogLog的方式来计算DistinctCount。好处是速度快,缺点是结果是一个近似值,会有一定的误差。在非计费等通常的场景下DistinctCount的统计误差应用普遍可以接受。
具体的算法可见论文
Apache kylin 与 RTOLAP
ApacheKylin 可以说是与市面上流行的Presto、SparkSQL、Impala等直接在原始数据上查询的系统(暂且归于RTOLAP)走了一条完全不同的道路。前者在如何快速求得预计算结果,以及优化查询解析使得更多的查询能用上预计算结果方面在优化。后续Kylin的版本会改进预计算引擎,优化预计算速度,使得Kylin可以变成一个近似实时的分析引擎。而像Presto,SparkSQL等是着重于优化查询数据的过程环节,像一些其它的数据仓库一样,使用列存、压缩、并行查询等技术,优化查询。这种方案的好处就在于扩展性强、能适配更广泛的查询。但是在查询速度上,可以说Apache Kylin 要比ROLAP 至少快上一个数量级,所以对与查询响应时间要求较高的应用,ApacheKylin是最好的选择。
Apache kylin的架构及核心组件
Apache kylin 架构如下:

核心组件:
- 数据立方体构建引擎(Cube Build Engine):当前底层数据计算引擎支持MapReduce1、MapReduce2、Spark等。
- Rest Server:当前kylin采用的ODBC, JDBC,RESTful API接口提供web服务。
- 查询引擎(Query Engine):REST Server接收查询请求后,解析sql语句,生成执行计划,然后转发查询请求到Hbase中,最后将结构返回给 REST Server。
Apache kylin SQL查询的实现
ANSI SQL查询是Apache Kylin 非常明显的优势。Kylin的SQL语法解析依赖于另一个开源数据管理框架 ApacheCalcite, Calcite即之前的Optiq,是一个没有存储模块的数据库,即不管理数据存储、不包含数据处理的算法,不包含元信息的存储。因此它非常适合来做一个应用到存储引擎之间的中间层。在Calcite的基础之上只要为存储引擎写一个专用的适配器(Adapter)即可形成一个功能丰富的支持DML甚至DDL的“类数据库”。
Kylin完成了一个定制的Adapter,在Calcite完成SQL解析,形成语法树(AST)之后,由Kylin定义语法树各个节点的执行规则来进行查询。Calcite在遍历语法树节点后生成一个Kylin描述查询模型的Digest, Kylin会为此Digest去判断是否有匹配的Cube。如果有与查询匹配的Cube,即选择一个查询代价最小的Cube进行查询(KylinCube的查询代价计算目前是一个开放接口,可以根据维度数目,可以根据数据量大小来计算Cost)
Kylin目前的多维数据存储引擎是HBase, Kylin利用了HBase的Coprocessor机制在HBase的RegionServer完成部分聚合以及全部过滤操作,在HbaseScan时提前进行计算,利用HBase多个Region Server的计算能力加速Kylin的SQL查询。目前Kylin仍然有部分查询语法不支持,特别是过滤器Where部分的约束较多、对SQL有一定的要求,但是如果有针对性的对Coprocessor部分进行改造相信SQL兼容度可以有大幅的提升。
Apache kylin配置
在Apache kylin的日常运维中,通常根据日常运行产生的日志调整相关配置参数,从而达到性能的提升和运行的稳定性,Apache kylin官网并没有给出这些配置的相关说明和解释,下面介绍一下Apache kylin的配置。
在${KYLIN_HOME}/conf 下一共4个配置文件:1
2
3
4
5
6
7 kylin_hive_conf.xml
kylin_job_conf_inmem.xml
kylin_job_conf.xml
kylin.properties
kylin_hive_conf.xml是kylin提交任务到hive的配置文件,kylin_job_conf_inmem.xml、kylin_job_conf.xml是 kylin提交任务到yarn中的配置文件,用户可根据自己的情况酌情修改,下面介绍一下kylin.properties的重要配置项:
kylin服务器的运行模式,有all、job、query1
> kylin.server.mode=all
kylin实例服务器列表,注意:不包括以job模式运行的服务器实例1
> kylin.rest.servers=hostname1:7070,hostname2:7070,hostname3:7070
kylin元数据配置1
> kylin.metadata.url=kylin_metadata@hbase
Apache kylin job的重试次数,注意:这个job指cube) build、fresh时生成的job,而不是每一个step 的mapreduce job。1
> kylin.job.retry=0
Apache kylin提交作业到hadoop中时,每个reduce的最大输入,该参数用来确定mapreduce的reduce个数,
1 | > kylin.job.mapreduce.default.reduce.input.mb=500. |
参见以下代码:1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34 public double getDefaultHadoopJobReducerInputMB() {
return Double.parseDouble(getOptional("kylin.job.mapreduce.default.reduce.input.mb", "500"));}
And
protected void setReduceTaskNum(Job job, KylinConfig config, String cubeName, int level) throws ClassNotFoundException, IOException, InterruptedException, JobException {
Configuration jobConf = job.getConfiguration();
KylinConfig kylinConfig = KylinConfig.getInstanceFromEnv();
CubeDesc cubeDesc = CubeManager.getInstance(config).getCube(cubeName).getDescriptor();
kylinConfig = cubeDesc.getConfig();
double perReduceInputMB = kylinConfig.getDefaultHadoopJobReducerInputMB();
double reduceCountRatio = kylinConfig.getDefaultHadoopJobReducerCountRatio();
// total map input MB
double totalMapInputMB = this.getTotalMapInputMB();
// output / input ratio
int preLevelCuboids, thisLevelCuboids;
if (level == 0) { // base cuboid
preLevelCuboids = thisLevelCuboids = 1;
} else { // n-cuboid
int[] allLevelCount = CuboidCLI.calculateAllLevelCount(cubeDesc);
preLevelCuboids = allLevelCount[level - 1];
thisLevelCuboids = allLevelCount[level];
}
// total reduce input MB
double totalReduceInputMB = totalMapInputMB * thisLevelCuboids / preLevelCuboids;
// number of reduce tasks
int numReduceTasks = (int) Math.round(totalReduceInputMB / perReduceInputMB * reduceCountRatio);
// adjust reducer number for cube which has DISTINCT_COUNT measures for better performance
if (cubeDesc.hasMemoryHungryMeasures()) {numReduceTasks = numReduceTasks * 4;}
// at least 1 reducer
numReduceTasks = Math.max(1, numReduceTasks);
// no more than 5000 reducer by default
numReduceTasks = Math.min(kylinConfig.getHadoopJobMaxReducerNumber(), numReduceTasks);
jobConf.setInt(MAPRED_REDUCE_TASKS, numReduceTasks);
logger.info("Having total map input MB " + Math.round(totalMapInputMB));logger.info("Having level " + level + ", pre-level cuboids " + preLevelCuboids + ", this level cuboids " + thisLevelCuboids);logger.info("Having per reduce MB " + perReduceInputMB + ", reduce count ratio " + reduceCountRatio);logger.info("Setting " + MAPRED_REDUCE_TASKS + "=" + numReduceTasks);}
用户可根据自己的数据量大小,性能要求及hadoop集群中的mapred-site.xml配置,酌情修改该项。1
> kylin.job.run.as.remote.cmd=false
该项配置表示,是否以ssh命令方式,向hadoop、hbase、hive等发起CLI命令。一般将kylin部署在hadoop集群的客户机上,所以该值为false。假如kylin服务不部署在hadoop的客户机上,则该值为true;这样kylin访问hadoop集群,需要给出以下配置项的值:1
2
3
4
5
6
7
8 # Only necessary when kylin.job.run.as.remote.cmd=true
kylin.job.remote.cli.hostname=
# Only necessary when kylin.job.run.as.remote.cmd=true
kylin.job.remote.cli.username=
# Only necessary when kylin.job.run.as.remote.cmd=true
kylin.job.remote.cli.password=
以下配置项是Apache kylin并发执行job的最大值:1
> kylin.job.concurrent.max.limit=10
Apache kylin检查提交yarn中的mapreduce任务状态的时间间隔:1
> kylin.job.yarn.app.rest.check.interval.seconds=10
代码如下:1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25 while (!isDiscarded()) {
JobStepStatusEnum newStatus = statusChecker.checkStatus();
if (status == JobStepStatusEnum.KILLED) {
executableManager.updateJobOutput(getId(), ExecutableState.ERROR, Collections.<String, StringemptyMap(), "killed by admin");
return new ExecuteResult(ExecuteResult.State.FAILED, "killed by admin");
}
if (status == JobStepStatusEnum.WAITING && (newStatus == JobStepStatusEnum.FINISHED || newStatus == JobStepStatusEnum.ERROR || newStatus == JobStepStatusEnum.RUNNING)) {
final long waitTime = System.currentTimeMillis() - getStartTime();
setMapReduceWaitTime(waitTime);
}
status = newStatus;
executableManager.addJobInfo(getId(), hadoopCmdOutput.getInfo());
if (status.isComplete()) {
final Map<String, Stringinfo = hadoopCmdOutput.getInfo();
readCounters(hadoopCmdOutput, info);
executableManager.addJobInfo(getId(), info);
if (status == JobStepStatusEnum.FINISHED) {
return new ExecuteResult(ExecuteResult.State.SUCCEED, output.toString());
}
else {
return new ExecuteResult(ExecuteResult.State.FAILED, output.toString());
}
}
Thread.sleep(context.getConfig().getYarnStatusCheckIntervalSeconds() * 1000);
}
以下配置项是kylin build cube)时的第一步建立hive中间表所在的数据库:1
> kylin.job.hive.database.for.intermediatetable=default
以下是kylin build cube)时在hbase中建表后,存储数据的压缩算法:1
> kylin.hbase.default.compression.codec=snappy
注意,设值时,先要检验hbase所指向的hadoop支不支持该压缩算法,检验命令如下:1
hadoop checknative -a
Apache Kylin元数据管理
Apache kylin元数据的存储
Apache Apache kylin的元数据包括 立方体描述(cube description),立方体实例(cube instances)项目(project)、作业(job)、表(table)、字典(dictionary),参见: Apache kylin 核心概念。在kylin集群中至关重要,假如元数据丢失,kylin集群将无法工作。

可见Apache kylin提供了两种方式存储元数据,一般而言,集群模式的元数据都选择在hbase中存储。在${KYLIN_HOME}/conf/kylin.properties中,元数据的默认配置如下:
kylin.metadata.url=kylin_metadata@hbase
kylin_metadata@hbase表示,元数据存储在hbase中的kylin_metadata表中。HBaseResourceStore#HBaseResourceStore的参考代码如下:1
2
3
4
5
6
7
8
9
10
11 public HBaseResourceStore(KylinConfig kylinConfig) throws IOException {
super(kylinConfig);
String metadataUrl = kylinConfig.getMetadataUrl();
// split TABLE@HBASE_URL
int cut = metadataUrl.indexOf('@');
tableNameBase = cut < 0 ? DEFAULT_TABLE_NAME : metadataUrl.substring(0, cut);
hbaseUrl = cut < 0 ? metadataUrl : metadataUrl.substring(cut + 1);
createHTableIfNeeded(getAllInOneTableName());
}
如若存储Apache kylin元数据在本地文件系统中,需将kylin.metadata.url 指向本地文件系统的一个绝对路径, 如:可在${KYLIN_HOME}/conf/kylin.properties中配置如下:1
kylin.metadata.url=/home/${username}/${kylin_home}/kylin_metada
注意,一定要是绝对路径,否则会出现错误。
当选择元数据存储在hbase中时,并非所有的数据都在hbase中,当待存储的记录(通常是key-value pairs)的value大于一个最大值kvSizeLimit时,数据将被保存在HDFS中,默认路径为:/kylin/kylin_metadata/,相关配置项在${KYLIN_HOME}/conf/kylin.properties中,如下:1
2> kylin.hdfs.working.dir=/kylin
> kylin.metadata.url=kylin_metadata@hbase
HBaseResourceStore#buildPut的参考代码如下:1
2
3
4
5
6
7
8
9
10
11
12
13private Put buildPut(String resPath, long ts, byte[] row, byte[] content, HTableInterface table) throws IOException {
int kvSizeLimit = this.kylinConfig.getHBaseKeyValueSize();
if (content.length kvSizeLimit) {
writeLargeCellToHdfs(resPath, content, table);
content = BytesUtil.EMPTY_BYTE_ARRAY;
}
Put put = new Put(row);
put.add(B_FAMILY, B_COLUMN, content);
put.add(B_FAMILY, B_COLUMN_TS, Bytes.toBytes(ts));
return put;
}
kvSizeLimit 的获取代码如下:
public int getHBaseKeyValueSize() { return Integer.parseInt(this.getOptional("kylin.hbase.client.keyvalue.maxsize", "10485760")); }
默认值为10M,可在在${KYLIN_HOME}/conf/kylin.properties中配置:1
> kylin.hbase.client.keyvalue.maxsize=10485760
注意,该值的大小十分重要,因为kylin为了提高整体性能将hbase中的元数据缓存在hbase内存中,如下图
Apache kylin元数据的运维
当前Apache kylin的元数据只提供了冷备份的方式。
可利用crontab 在${KYLIN_HOME}下,每天定时执行./bin/metastore.sh backup命令,kylin会将元数据信息保存如下目录:
${KYLIN_HOME}/meta_backups/meta_year_month_day_hour_minute_second
当kylin元数据损坏或不一致,可采用如下命令恢复:
1 | cd ${KYLIN_HOME} |
Apache kylin-Slow Query SQL改造
慢查询(Slow Query SQL)定性
在Apache Apache kylin中,一旦cube)经过build、refresh或merge后,将对外提供基于ODBC、JDBC、RESTful API等接口的亚秒级OLAP功能;尽管如此,在生产环境中,我们仍然需要记录执行结果很慢的sql语句,并发出告警,以便分析、优化。
在kylin的query engine 端,有一个后台线程BadQueryDetector不断去发现前端请求的错误的sql语句,当然包括slow query sql,核心代码如下:1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16 public void run() {
while (true) {
try {
Thread.sleep(detectionInterval);
} catch (InterruptedException e) {
// stop detection and exit
return;
}
try {
detectBadQuery();
} catch (Exception ex) {
logger.error("", ex);
}
}
}
BadQueryDetector#detectBadQuery 代码如下:1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21 private void detectBadQuery() {
long now = System.currentTimeMillis();
ArrayList<Entryentries = new ArrayList<Entry>(runningQueries.values());
Collections.sort(entries);
// report if query running long
for (Entry e : entries) {
float runningSec = (float) (now - e.startTime) / 1000;
if (runningSec >= alertRunningSec) {
notify("Slow", runningSec, e.startTime, e.sqlRequest.getProject(), e.sqlRequest.getSql(), e.thread);
dumpStackTrace(e.thread);
} else {
break; // entries are sorted by startTime
}
}
// report if low memory
if (getSystemAvailMB() < alertMB) {
logger.info("System free memory less than " + alertMB + " MB. " + entries.size() + " queries running.");
}
}
即当sql的执行时间大于 alertRunningSec,kylin将其定性为 slow query sql,alertRunningSec的获取如下:1
2
3
4
5
6
7
8
9
10 public BadQueryDetector() {
super("BadQueryDetector");
this.setDaemon(true);
this.kylinConfig = KylinConfig.getInstanceFromEnv();
this.detectionInterval = kylinConfig.getBadQueryDefaultDetectIntervalSeconds() * 1000;
this.alertMB = 100;
this.alertRunningSec = kylinConfig.getBadQueryDefaultAlertingSeconds();
initNotifiers();
}
以及1
2
3 public int getBadQueryDefaultAlertingSeconds() {
return Integer.parseInt(getOptional("kylin.query.badquery.alerting.seconds", "90"));
}
可见当sql的响应时间超过90秒,kylin才会将其视为slow query sql, 显然,对于一个提供实时查询的OLAP系统,这个指标的设置是不合理的。在${KYLIN_HOME}/conf/kylin.properties中修改如下:1
> kylin.query.badquery.alerting.seconds=3
告警改造
当前 slow query sql的发现及输出采用观察者模式,用户可以通过实现接口 Notifier 自定义观察者,然后注册给BadQueryDetector。1
2
3> public interface Notifier {
> void badQueryFound(String adj, float runningSec, long startTime, String project, String sql, Thread t);
> }
以及1
2
3 public void registerNotifier(Notifier notifier) {
notifiers.add(notifier);
}
当前BadQueryDetector有两个内置观察者,LoggerNotifier和PersistenceNotifier,其中LoggerNotifier将slow query sql 记录到日志;PersistenceNotifier将记录至元数据(一般是hbase)。
出于运维需要,我们可以自定义观察者,将slow qeury sql发送到业务负责人的邮箱或者手机。如:1
2
3
4
5
6 public class EmailNotifier implements Notifier {
void badQueryFound(String adj, float runningSec, long startTime, String project, String sql, Thread t){
//send a email;
}
}
slow query sql 在元数据中的位置
当元数据配置采用默认配置时,即:
kylin.metadata.url=kylin_metadata@hbase
元数据在以下位置:1
2
3
4
5
6
7 1)表 : kylin_metadata
2)rowKey : /bad_query/${project_name}.json // 用UTF-8 编码
3) column: f:c // content: slow sql的具体内容,需先用UTF-8解码,然后用 JsonSerializer 反序列化
column: f:t //timestamp : 更新该条记录的 时间戳
Kylin on Docker
This repository trackes the code and files for building docker images with Apache Kylin.
此部分描述在 docker中运行Kylin的代码和过程
How to make it
The main idea is building Hadoop/HBase/Hive clients and Kylin binary package into one image; User can pull this image, and then just add client configuration files like core-site.xml, hdfs-site.xml, yarn-site.xml, hbase-site.xml, hive-site.xml and kylin.properties to the effective paths to make a new image (has verified), or upload these files during starting up (not verified yet);
主要的思路是打包Hadoop/HBase/Hive的客户端以及Kylin的二进制包进一个镜像,用户可以拉取这个镜像并且增加客户端配置文件(例如core-site.xml, hdfs-site.xml, yarn-site.xml, hbase-site.xml, hive-site.xml and kylin.properties)进有效路径创建一个新镜像。
Before start, you need do some preparations:
开始之前,需要做如下准备
- check the Hadoop versions, and make sure the client libs in the image are compitable with the cluster;
- 检查 hadoop 版本,确保镜像中的客户端包与集群兼容。
- prepare a kylin.properties file for this deployment;
- 为部署准备一个kylin.properties 文件
- ensure the Hadoop security constraint will not block Docker’s adoption; you may need run additional component in the container if kerberos is enabled.
- 确保 hadoop 安全组建不会阻止docker的适配。如果需要使用kerberos,有可能需要运行额外组件。
Steps
Below is a sample of building and running a docker image for Hortonworks HDP 2.2 cluster.
下面是一个在Hortonworks HDP 2.2 集群上构建和运行一个docker镜像的例子。
Collect the client configuration files Get the *-site.xml files from a working Hadoop client node, to a local folder say
1
"~/hadoop-conf/";
Prepare kylin.properties
The kylin.properties file is the main configuration file for Kylin; you need prepare such a file and put it to the “~/hadoop-conf/“ folder, together with other conf files; suggest to double check the parameters in it; e.g, the “kylin.metadata.url” points to the right metadata table, “kylin.hdfs.working.dir” is an existing HDFS folder and you have permission to write, etc.
Clone this repository, checkout the correct branch;
1
2
3git clone https://github.com/Kyligence/kylin-docker
cd kylin-docker
git checkout kylin152-hdp22Copy the client configuration files to “kylin-docker/conf” folder, overwriting those template files;
1
> cp -rf ~/hadoop-conf/* conf/
Build docker image, which may take a while, just take a cup of tea;
1
docker build -t kyligence/kylin:152 .
After the build finished, should be able to see the image with “docker images” commmand;1
2
3> [root@ip-10-0-0-38 ~]# docker images
> REPOSITORY TAG IMAGE IDCREATED VIRTUAL SIZE
> kyligence/kylin 152 7ece32097fa3About an hour ago 3.043 GB
Now you can run a contianer with the bootstrap command (in which will start Kylin server). The “-bash” argument is telling to keep in bash so you can continue to run bash commands; If don’t need, you can use the “-d” argument:
1
2
3
4
5
6
7
8
9
10
11
12
13
14[root@ip-10-0-0-38 ~]# docker run -i -t -p 7070:7070 kyligence/kylin:152 /etc/bootstrap.sh -bash
Generating SSH1 RSA host key: [ OK ]
Starting sshd: [ OK ]
KYLIN_HOME is set to /usr/local/kylin/bin/../
kylin.security.profile is set to ldap
16/06/30 04:50:31 WARN conf.HiveConf: HiveConf of name hive.optimize.mapjoin.mapreduce does not exist
16/06/30 04:50:31 WARN conf.HiveConf: HiveConf of name hive.heapsize does not exist
16/06/30 04:50:31 WARN conf.HiveConf: HiveConf of name hive.server2.enable.impersonation does not exist
16/06/30 04:50:31 WARN conf.HiveConf: HiveConf of name hive.auto.convert.sortmerge.join.noconditionaltask does not exist
Logging initialized using configuration in file:/etc/hive/conf/hive-log4j.properties
HCAT_HOME not found, try to find hcatalog path from hadoop home
A new Kylin instance is started by , stop it using "kylin.sh stop"
Please visit http://<ip>:7070/kylin
You can check the log at /usr/local/kylin/bin/..//logs/kylin.logAfter a minute, you can open web browser with address http://host:7070/kylin , here the “host” is the hostname or IP address of the hosting machine which runs Docker; Its 7070 port will redirect to the contianer’s 7070 port as we specified in the “docker run” command; You can change to other port as you like.
Now you can use Kylin as usually: import Hive tables, design cubes, build, query, etc.
Kylin 接口
ODBC接口
We provide Kylin ODBC driver to enable data access from ODBC-compatible client applications.
Both 32-bit version or 64-bit version driver are available.
Tested Operation System: Windows 7, Windows Server 2008 R2
Tested Application: Tableau 8.0.4, Tableau 8.1.3 and Tableau 9.1
Prerequisites
- Microsoft Visual C++ 2012 Redistributable
- For 32 bit Windows or 32 bit Tableau Desktop: Download: 32bit version
- For 64 bit Windows or 64 bit Tableau Desktop: Download: 64bit version
- ODBC driver internally gets results from a REST server, make sure you have access to one
Installation
- Uninstall existing Kylin ODBC first, if you already installled it before
- Download ODBC Driver from download.
- For 32 bit Tableau Desktop: Please install KylinODBCDriver (x86).exe
- For 64 bit Tableau Desktop: Please install KylinODBCDriver (x64).exe
- Both drivers already be installed on Tableau Server, you properly should be able to publish to there without issues
DSN configuration
Open ODBCAD to configure DSN.
For 32 bit driver, please use the 32bit version in C:\Windows\SysWOW64\odbcad32.exe
For 64 bit driver, please use the default “Data Sources (ODBC)” in Control Panel/Administrator Tools
JDBC接口
Authentication
Build on kylin authentication restful service. Supported parameters:1
2
3> 1. user : username
> 2. password : password
> 3. ssl: true/false. Default be false; If true, all the services call will use https.
Connection URL format:
jdbc:kylin://<hostname>:<port>/<kylin_project_name>
- If “ssl” = true, the “port” should be Kylin server’s HTTPS port;
- If “port” is not specified, the driver will use default port: HTTP 80, HTTPS 443;
- The “kylin_project_name” must be specified and user need ensure it exists in Kylin server;
Query with Statement1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23 Driver driver = (Driver) Class.forName("org.apache.kylin.jdbc.Driver").newInstance();
Properties info = new Properties();
info.put("user", "ADMIN");
info.put("password", "KYLIN");
Connection conn = driver.connect("jdbc:kylin://localhost:7070/kylin_project_name", info);
Statement state = conn.createStatement();
ResultSet resultSet = state.executeQuery("select * from test_table");
while (resultSet.next()) {
assertEquals("foo", resultSet.getString(1));
assertEquals("bar", resultSet.getString(2));
assertEquals("tool", resultSet.getString(3));
}
Query with PreparedStatement
Supported prepared statement parameters:
- setString
- setInt
- setShort
- setLong
- setFloat
- setDouble
- setBoolean
- setByte
- setDate
- setTime
- setTimestamp
1
2
3
4
5
6
7
8
9
10
11
12
13
14Driver driver = (Driver) Class.forName("org.apache.kylin.jdbc.Driver").newInstance();
Properties info = new Properties();
info.put("user", "ADMIN");
info.put("password", "KYLIN");
Connection conn = driver.connect("jdbc:kylin://localhost:7070/kylin_project_name", info);
PreparedStatement state = conn.prepareStatement("select * from test_table where id=?");
state.setInt(1, 10);
ResultSet resultSet = state.executeQuery();
while (resultSet.next()) {
assertEquals("foo", resultSet.getString(1));
assertEquals("bar", resultSet.getString(2));
assertEquals("tool", resultSet.getString(3));
}
Get query result set metadata
Kylin jdbc driver supports metadata list methods:
List catalog, schema, table and column with sql pattern filters(such as %).1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26 Driver driver = (Driver) Class.forName("org.apache.kylin.jdbc.Driver").newInstance();
Properties info = new Properties();
info.put("user", "ADMIN");
info.put("password", "KYLIN");
Connection conn = driver.connect("jdbc:kylin://localhost:7070/kylin_project_name", info);
Statement state = conn.createStatement();
ResultSet resultSet = state.executeQuery("select * from test_table");
ResultSet tables = conn.getMetaData().getTables(null, null, "dummy", null);
while (tables.next()) {
for (int i = 0; i < 10; i++) {
assertEquals("dummy", tables.getString(i + 1));
}
}
RESTful 接口
Build Cube with RESTful API
Authentication
- Currently, Kylin uses basic authentication.
- Add Authorization header to first request for authentication
- Or you can do a specific request by POST http://localhost:7070/kylin/api/user/authentication
- Once authenticated, client can go subsequent requests with cookies.
1
2
3
4POST http://localhost:7070/kylin/api/user/authentication
Authorization:Basic xxxxJD124xxxGFxxxSDF
Content-Type: application/json;charset=UTF-8
Get details of cube.
- GET http://localhost:7070/kylin/api/cubes?cubeName={cube_name}&limit=15&offset=0
- Client can find cube segment date ranges in returned cube detail.
1
2
3
4GET http://localhost:7070/kylin/api/cubes?cubeName=test_kylin_cube_with_slr&limit=15&offset=0
Authorization:Basic xxxxJD124xxxGFxxxSDF
Content-Type: application/json;charset=UTF-8
Then submit a build job of the cube.
- PUT http://localhost:7070/kylin/api/cubes/{cube_name}/rebuild
- For put request body detail please refer to Build Cube API.
- startTime and endTime should be utc timestamp.
- buildType can be BUILD ,MERGE or REFRESH. BUILD is for building a new segment, REFRESH for refreshing an existing segment. MERGE is for merging multiple existing segments into one bigger segment.
- This method will return a new created job instance, whose uuid is the unique id of job to track job status.
1
2
3
4
5
6
7
8
9
10PUT http://localhost:7070/kylin/api/cubes/test_kylin_cube_with_slr/rebuild
Authorization:Basic xxxxJD124xxxGFxxxSDF
Content-Type: application/json;charset=UTF-8
{
"startTime": 0,
"endTime": 1388563200000,
"buildType": "BUILD"
}
Track job status.
- GET http://localhost:7070/kylin/api/jobs/{job_uuid}
Returned job_status represents current status of job.
If the job got errors, you can resume it.
Use RESTful API in Javascript
Kylin security is based on basic access authorization, if you want to use API in your javascript, you need to add authorization info in http headers.
Example on Query API.
1 | $.ajaxSetup({ |
Keypoints
- add basic access authorization info in http headers.
- use right ajax type and data synax.
Basic access authorization
- For what is basic access authorization, refer to Wikipedia Page.
- How to generate your authorization code (download and import “jquery.base64.js” from https://github.com/yckart/jquery.base64.js).
1
2
3
4
5
6
7
8var authorizationCode = $.base64('encode', 'NT_USERNAME' + ":" + 'NT_PASSWORD');
$.ajaxSetup({
headers: {
'Authorization': "Basic " + authorizationCode,
'Content-Type': 'application/json;charset=utf-8'
}
});
Use RESTful API
Authentication
1 | POST /user/authentication |
Request Header
Authorization data encoded by basic auth is needed in the header, such as:
Authorization:Basic {data}
Response Body
- userDetails - Defined authorities and status of current user.
Response Sample
1 | { |
Example with curl:1
> curl -c /path/to/cookiefile.txt -X POST -H "Authorization: Basic XXXXXXXXX" -H 'Content-Type: application/json' http://<host>:<port>/kylin/api/user/authentication
If login successfully, the JSESSIONID will be saved into the cookie file; In the subsequent http requests, attach the cookie, for example:1
> curl -b /path/to/cookiefile.txt -X PUT -H 'Content-Type: application/json' -d '{"startTime":'1423526400000', "endTime":'1423526400', "buildType":"BUILD"}' http://<host>:<port>/kylin/api/cubes/your_cube/rebuild
Query
1 | POST /query |
Request Body
- sql - required string The text of sql statement.
- offset - optional int Query offset. If offset is set in sql, curIndex will be ignored.
- limit - optional int Query limit. If limit is set in sql, perPage will be ignored.
- acceptPartial - optional bool Whether accept a partial result or not, default be “false”. Set to “false” for production use.
- project - optional string Project to perform query. Default value is ‘DEFAULT’.
Request Sample
1
2
3
4
5
6
7{
"sql":"select * from TEST_KYLIN_FACT",
"offset":0,
"limit":50000,
"acceptPartial":false,
"project":"DEFAULT"
}
Response Body
- columnMetas - Column metadata information of result set.
- results - Data set of result.
- cube - Cube used for this query.
- affectedRowCount - Count of affected row by this sql statement.
- isException - Whether this response is an exception.
- ExceptionMessage - Message content of the exception.
- Duration - Time cost of this query
- Partial - Whether the response is a partial result or not. Decided by acceptPartial of request.
Response Sample
1 | { |
List queryable tables
1 | > GET /tables_and_columns |
Request Parameters
- project - required string The project to load tables
Response Sample
1 | [ |
List cubes
1 | > GET /cubes |
Request Parameters
- offset - required int Offset used by pagination
- limit - required int Cubes per page.
- cubeName - optional string Keyword for cube names. To find cubes whose name contains this keyword.
- projectName - optional string Project name.
Response Sample
1 |
|
Get cube
1 | > GET /cubes/{cubeName} |
Path Variable
- cubeName - required string Cube name to find.
1
2
3> Get cube descriptor
> GET /cube_desc/{cubeName}
> Get descriptor for specified cube instance.
Path Variable
- cubeName - required string Cube name.
Response Sample
1 | [ |
Get data model
1 | > GET /model/{modelName} |
Path Variable
- modelName - required string Data model name, by default it should be the same with cube name.
Response Sample
1 | { |
Build cube
1 | > PUT /cubes/{cubeName}/rebuild |
Path Variable
- cubeName - required string Cube name.
Request Body
- startTime - required long Start timestamp of data to build, e.g. 1388563200000 for 2014-1-1
- endTime - required long End timestamp of data to build
- buildType - required string Supported build type: ‘BUILD’, ‘MERGE’, ‘REFRESH’
Response Sample
1 | { |
Enable Cube
1 | PUT /cubes/{cubeName}/enable |
Path variable
- cubeName - required string Cube name.
Response Sample
1 | { |
Disable Cube
1 | PUT /cubes/{cubeName}/disable |
Path variable
(Same as “Enable Cube”)
Purge Cube
1 | > PUT /cubes/{cubeName}/Purge |
Path variable
(Same as “Enable Cube”)
Resume Job
1 | PUT /jobs/{jobId}/resume |
Path variable
- jobId - required string Job id.
Response Sample
1 | { |
Discard Job
1 | PUT /jobs/{jobId}/cancel |
Path variable
- jobId - required string Job id.
Response Sample
(Same as “Resume job”)
Get Job Status
1 | GET /jobs/{jobId} |
Path variable
(Same as “Resume Job”)
Get job step output
1 | > GET /jobs/{jobId}/steps/{stepId}/output |
Path Variable
- jobId - required string Job id.
- stepId - required string Step id; the step id is composed by jobId with step sequence id; for example, the jobId is “fb479e54-837f-49a2-b457-651fc50be110”, its 3rd step id is “fb479e54-837f-49a2-b457-651fc50be110-3”,
Response Sample
1
2
3{
"cmd_output":"log string"
}
Get Hive Table
GET /tables/{tableName}
Request Parameters
- tableName - required string table name to find.
Response Sample
1 | { |
Get Hive Table (Extend Info)
1 | > /tables/{tableName}/exd- |
Request Parameters
- tableName - optional string table name to find.
Response Sample
1 | { |
Get Hive Tables
1 | > GET /tables |
Request Parameters
- project- required string will list all tables in the project.
- ext- optional boolean set true to get extend info of table.
Response Sample
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43[
{
uuid: "53856c96-fe4d-459e-a9dc-c339b1bc3310",
name: "SAMPLE_08",
columns: [{
id: "1",
name: "CODE",
datatype: "string"
}, {
id: "2",
name: "DESCRIPTION",
datatype: "string"
}, {
id: "3",
name: "TOTAL_EMP",
datatype: "int"
}, {
id: "4",
name: "SALARY",
datatype: "int"
}],
database: "DEFAULT",
cardinality: {},
last_modified: 0,
exd: {
minFileSize: "46069",
totalNumberFiles: "1",
location: "hdfs://sandbox.hortonworks.com:8020/apps/hive/warehouse/sample_08",
lastAccessTime: "1398176495945",
lastUpdateTime: "1398176495981",
columns: "struct columns { string code, string description, i32 total_emp, i32 salary}",
partitionColumns: "",
EXD_STATUS: "true",
maxFileSize: "46069",
inputformat: "org.apache.hadoop.mapred.TextInputFormat",
partitioned: "false",
tableName: "sample_08",
owner: "hue",
totalFileSize: "46069",
outputformat: "org.apache.hadoop.hive.ql.io.HiveIgnoreKeyTextOutputFormat"
}
}
]
Load Hive Tables
1 | > POST /tables/{tables}/{project} |
Request Parameters
- tables - required string table names you want to load from hive, separated with comma.
- project - required String the project which the tables will be loaded into.
Response Sample
1
2
3
4{
"result.loaded": ["DEFAULT.SAMPLE_07"],
"result.unloaded": ["sapmle_08"]
}
Wipe cache
1 | > PUT /cache/{type}/{name}/{action} |
Path variable
- type - required string ‘METADATA’ or ‘CUBE’
- name - required string Cache key, e.g the cube name.
- action - required string ‘create’, ‘update’ or ‘drop’
Web Interface
1 | Supported Browsers |
Access & Login
Host to access: http://your_sandbox_ip:7070
Login with username/password: ADMIN/KYLI
Available Hive Tables in Kylin
Although Kylin will using SQL as query interface and leverage Hive metadata, kylin will not enable user to query all hive tables since it’s a pre-build OLAP (MOLAP) system so far. To enable Table in Kylin, it will be easy to using “Sync” function to sync up tables from Hive.
Kylin OLAP Cube
Kylin’s OLAP Cubes are pre-calculation datasets from Star Schema Hive tables, Here’s the web management interface for user to explorer, manage all cubes.Go to Cubes Menu, it will list all cubes available in system:
To explore more detail about the Cube
Form View:

SQL View (Hive Query to read data to generate the cube):

Visualization (Showing the Star Schema behind of this cube):

- Access (Grant user/role privileges, Grant operation only open to Admin in beta):

Write and Execute SQL on web
Kylin’s web offer a simple query tool for user to run SQL to explorer existing cube, verify result and explorer the result set using #5’s Pivot analysis and visualization
Query Limit
- Only SELECT query be supported
- To avoid huge network traffic from server to client, the scan range’s threshold be set to 1,000,000 in beta.
- SQL can’t found data from cube will not redirect to Hive in beta
Go to “Query” menu:
Source Tables:
Browser current available Tables (same structure and metadata as Hive):
- New Query:
You can write and execute your query and explorer the result. One query for you reference: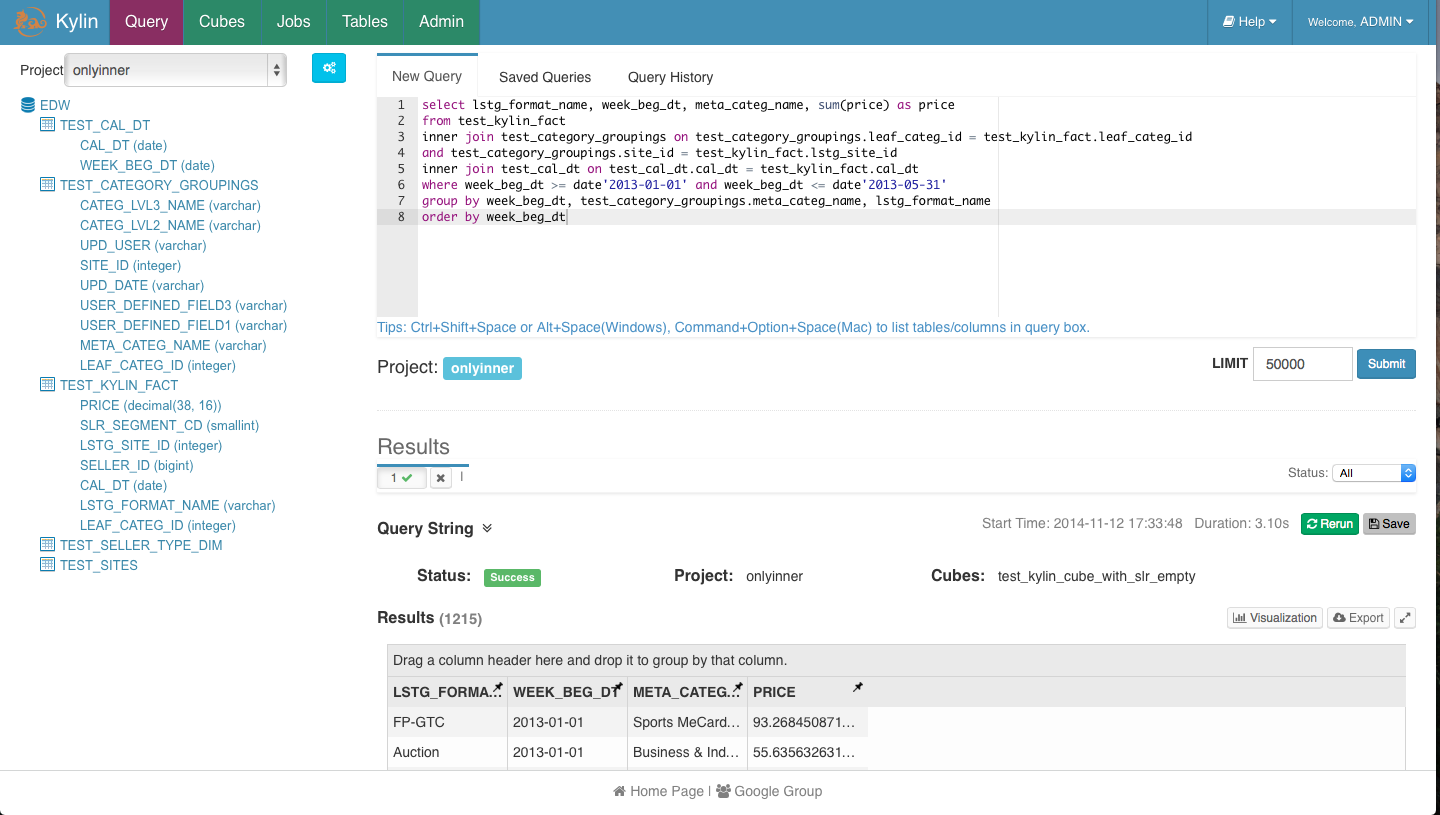
- Saved Query:
Associate with user account, you can get saved query from different browsers even machines.
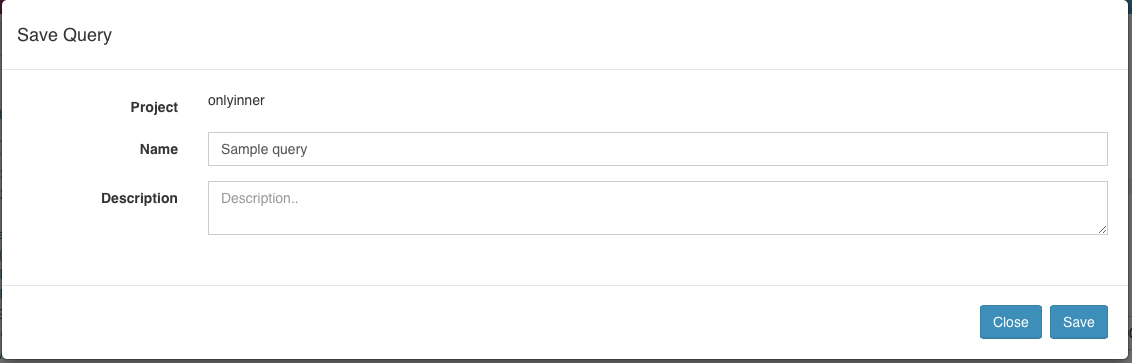
Click “Save” in Result area, it will popup for name and description to save current query:
Click “Saved Queries” to browser all your saved queries, you could direct resubmit it to run or remove it:
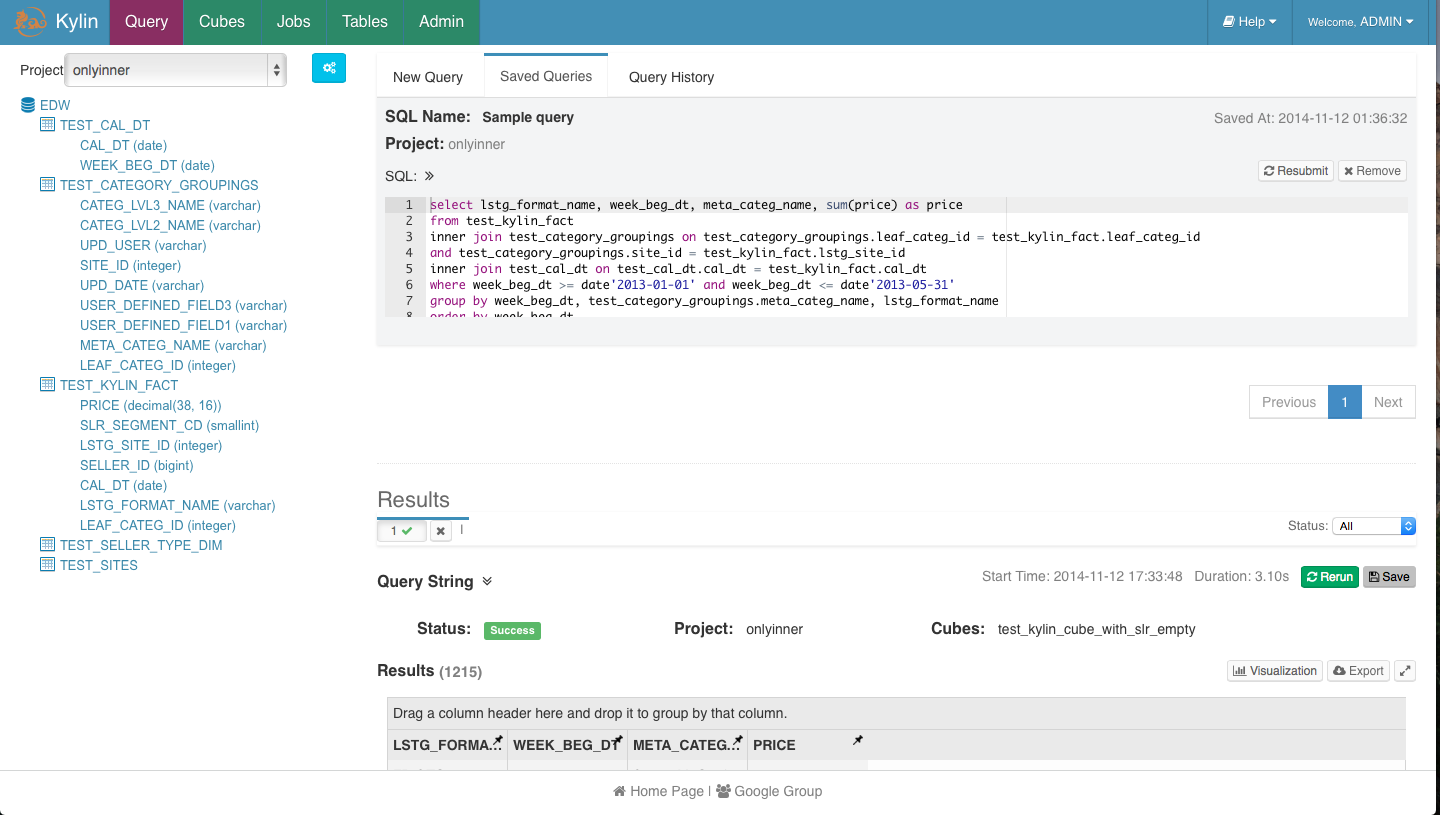
- Query History:
Only keep the current user’s query history in current bowser, it will require cookie enabled and will lost if you clean up bowser’s cache.Click “Query History” tab, you could directly resubmit any of them to execute again.
Pivot Analysis and Visualization
There’s one simple pivot and visualization analysis tool in Kylin’s web for user to explore their query result:
General Information:
When the query execute success, it will present a success indictor and also a cube’s name which be hit.
Also it will present how long this query be executed in backend engine (not cover network traffic from Kylin server to browser):
Query Result:
It’s easy to order on one column.
- Export to CSV File
Click “Export” button to save current result as CSV file.
- Pivot Table:
Drag and Drop one or more columns into the header, the result will grouping by such column’s value:
- Visualization:
Also, the result set will be easy to show with different charts in “Visualization”:
note: line chart only available when there’s at least one dimension with real “Date” data type of column from Hive Table.
Bar Chart:
Pie Chart:
Line Chart
kylin Client Tool Tutorial
Kylin-client-tool is a tool coded with python, completely based on Kylin’s restful apis.
With it, users can easily create Kylin Cubes, timely build cubes, summit/schedule/check/cancel/resume jobs.
Install
Make sure python2.6/2.7 installed
Two python packages apscheduler and requests are needed, run setup.sh to install. For mac users, please runsetup-mac.sh. Or you can install them with setuptools.
Settings
Modify settings/settings.py to set,
KYLIN_USER Kylin’s username KYLIN_PASSWORD Kylin’s password KYLIN_REST_HOST Kylin’s address KYLIN_REST_PORT Kylin’s port KYLIN_JOB_MAX_COCURRENT Max concurrent jobs for cube building KYLIN_JOB_MAX_RETRY Max failover time after job failed
About command lines
This tool is used by command lines, please run python kylin_client_tool.py -h to check for details.
Cube’s creation
This tool has its own cube definition method, the format is as below,
cube name|fact table name|dimension1,type of dimension1;dimension2,type of dimension2...|measure1,expression of measure1,type of measure1...|settings|filter| settings has options below, no_dictionary Set dimensions not generate dictionaries in “Rowkeys” and their lengths mandatory_dimension Set mandatory dimensions in “Rowkeys” aggregation_group Set aggregation group partition_date_column Set partition date column partition_date_start Set partition start date Cases can be found in file cube_def.csv, it does not support cube creation with lookup table Use -c to create, use -F to specify cube definition file, for instance python kylin_client_tool.py -c -F cube_def.csv
Build cube
Build cube with cube definition file
Use -b to build, use -F to specify the cube definition file, if “partition date column” specified, use -T to specify the end date(year-month-day), if not specified, it will take current time as end date, for instance,
python kylin_client_tool.py -b -F cube_def.csv -T 2016-03-01
Build cube with file of cube names
Use -f to specify the file of cube names, each line of the file has one cube name, for instance,
python kylin_client_tool.py -b -f cube_names.csv -T 2016-03-01
Build cube with cube names
Use -C to specify cube names, split with commas, for instance,
python kylin_client_tool.py -b -C client_tool_test1,client_tool_test2 -T 2016-03-01
Job management
Check jobs’ statuses
Use -s to check, use -f to specify file of cube names, use -C to specify cube names, if not specified, it will check all cubes’ statuses. Use -S to specify jobs’ statuses, R for Running, E for Error, F for Finished, D for Discarded, for instance,
python kylin_client_tool.py -s -C kylin_sales_cube -f cube_names.csv -S F
Resume jobs
Use -r to resume jobs, use -f to specify file of cube names, use -C to specify cube names, if not specified, it will reuse all jobs with error status, for instance,
python kylin_client_tool.py -r -C kylin_sales_cube -f cube_names.csv
Cancel jobs
Use -k to cancel jobs, use -f to specify file with cube names, use -C to specify cube names, if not specified, it will cancel all jobs with running or error statuses, for instance,
python kylin_client_tool.py -k -C kylin_sales_cube -f cube_names.csv
Schedule cubes building
Build cube at set intervals
On the basis of command of cube building, use -B i to specify the mode of build cube at set intervals, use -O to specify how many hours, for instance,
python kylin_client_tool.py -b -F cube_def.csv -B i -O 1
Build cube at given time
Use -B t to specify the mode of build cube at given time, use -O to specify the build time, split with commas,for instance,
python kylin_client_tool.py -b -F cube_def.csv -T 2016-03-04 -B t -O 2016,3,1,0,0,0

